

DMTN-224
RSP identity management implementation strategy#
Abstract
The identity management, authentication, and authorization component of the Rubin Science Platform is responsible for maintaining a list of authorized users and their associated identity information, authenticating their access to the Science Platform, and determining which services they are permitted to use. This tech note describes the technical details of the implementation of that system.
This is a description of the implementation as it stood at the time of last modification of this tech note. The identity management system is not complete. Additional functionality will be added in the future, and this tech note will be updated at that time to include those implementation details. For a list of remaining work, see the remaining work section of SQR-069.
Note
This is part of a tech note series on identity management for the Rubin Science Platform. The other primary documents are DMTN-234, which describes the high-level design; and SQR-069, which provides a history and analysis of the decisions underlying the design and implementation. See References for a complete list of related documents.
Implementation overview#
The primary components of the identity management system for the Rubin Science Platform are:
Some external source of user authentication
A repository of identity information about users (name, email, group membership, etc.)
A Kubernetes service (Gafaelfawr) which runs in each Science Platform deployment, performs user authentication, applies high-level access control rules, and provides identity information to other Science Platform services via an API
A configuration of the ingress-nginx Kubernetes ingress controller that uses Gafaelfawr as an auth subrequest handler to enforce authentication and authorization requirements
A user interface for creating and managing tokens, currently implemented as part of Gafaelfawr
The Science Platform in general, and specifically the last three components listed above, are deployed in a Kubernetes cluster using Phalanx. The first two components are external to the Kubernetes cluster in which the Science Platform runs.
Here is that architecture in diagram form:
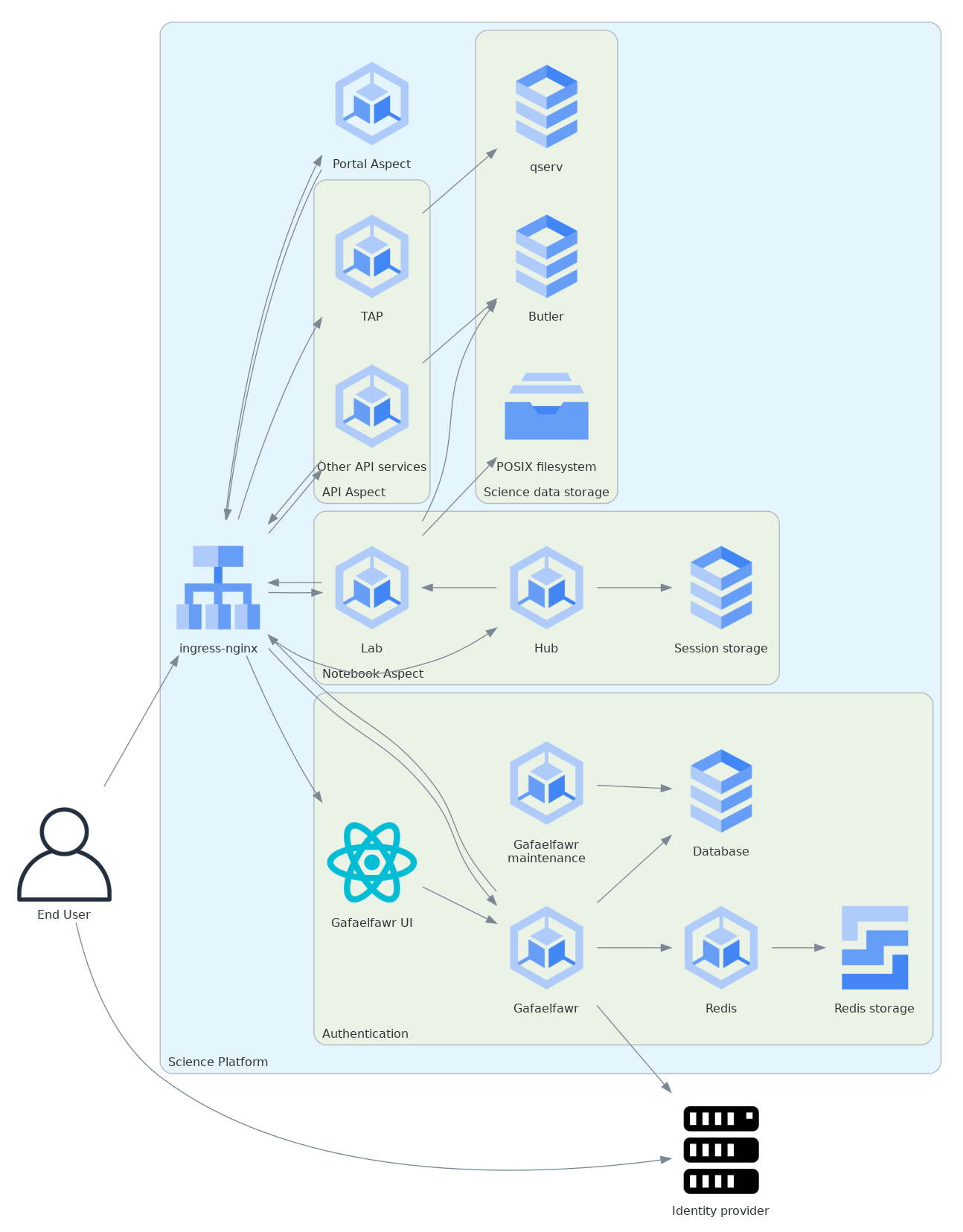
This shows the major aspects of the Science Platform but omits considerable detail, including most supporting services, the identity management store, and some details of the Gafaelfawr architecture.
As discussed in DMTN-234, there is no single Rubin Science Platform. There are multiple deployments of the Science Platform at different sites with different users and different configurations. With respect to the identity management system, these differ primarily in the choice of the first two components.
For federated identity deployments, we have chosen CILogon as the source of user authentication and COmanage as the repository of identity information. Here is the architecture for those deployments, expanding the identity management portion and simplifying the rest of the Science Platform to a single protected service:
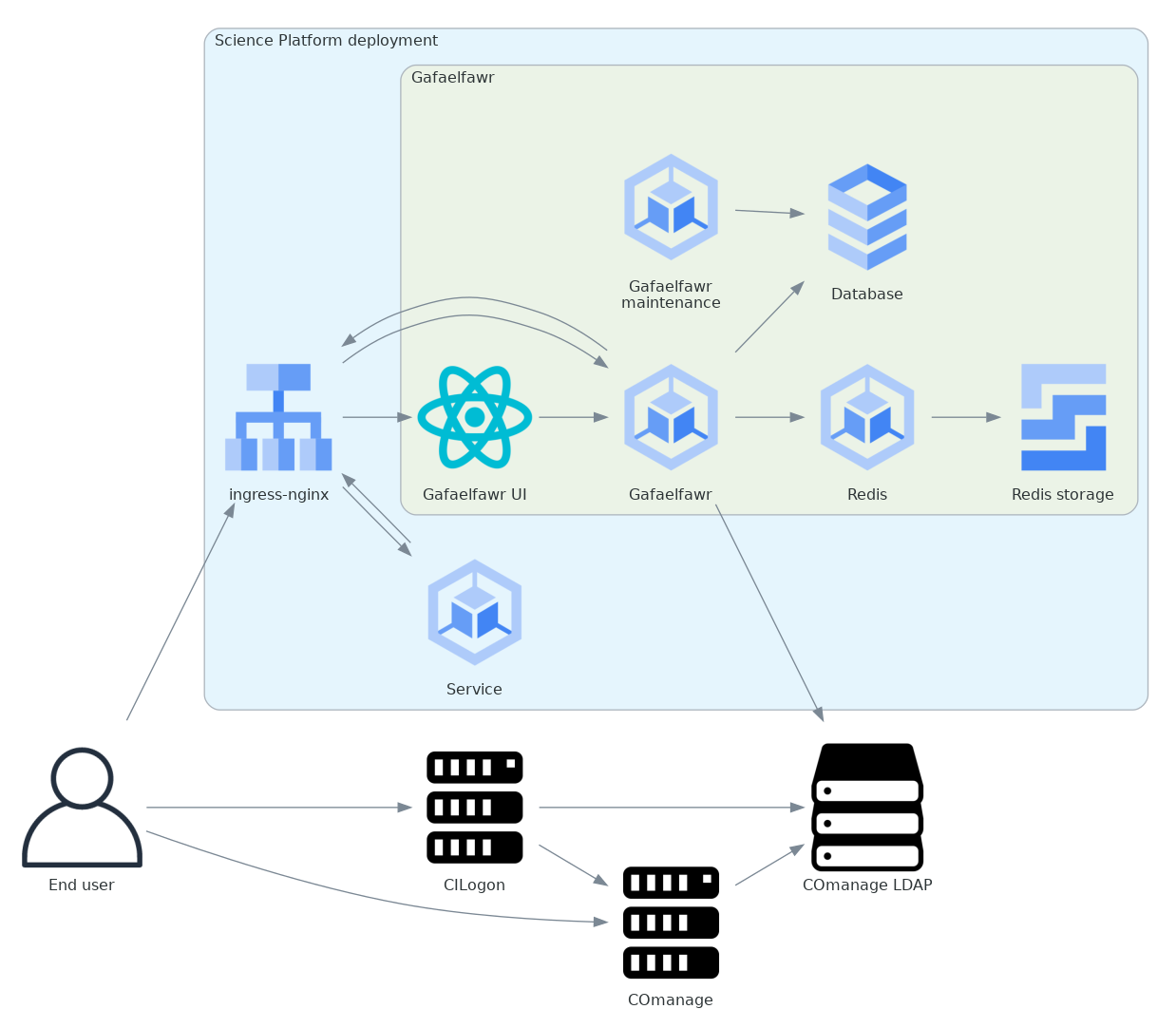
The Science Platform aspects and services are represented here by a single service to make the diagram simpler.
The other two supported options are to use GitHub for both authenitcation and identity mangaement, or to use a local OpenID Connect authentication provider as the source of user authentication. In the latter case, user identity information can come either from the OpenID Connect authentication provider or from a local LDAP server.
A deployment that uses GitHub looks essentially identical to the first architecture diagram, with GitHub as the identity provider. One that uses OpenID Connect is similar, but will likely separate the identity provider box into an OpenID Connect provider and an LDAP server that will be queried for metadata. It’s possible to use only claims from the OpenID Connect provider for all identity information, but usually it’s more convenient to use a local LDAP server.
The identity management system is largely identical in those three deployment options. Where there are differences, they will be mentioned specifically in the following discussion.
Identity management#
The identity management component of the system authenticates the user and maps that authentication to identity information.
When federated identity is required, authentication is done via the OpenID Connect protocol using CILogon. CILogon gives the user the option SAML authentication (used by most identity federations such as InCommon) or other identity providers such as GitHub and Google, and then communicates the resulting authentication information to Gafaelfawr with OpenID Connect. The other supported deployment options are an OAuth 2.0 authentication request to GitHub or an OpenID Connect authentication request to a local identity provider.
Once the user has been authenticated, their identity must be associated with additional information: full name, email address, numeric UID, primary GID, group membership, and numeric GIDs for the groups. In deployments using federated identity, most of this data comes from COmanage (via LDAP), and numeric UIDs and GIDs come from Firestore. For GitHub deployments, access to the user’s profile and organization membership is requested as part of the OAuth 2.0 request, and then retrieved after authentication with the token obtained by the OAuth 2.0 authentication. See GitHub for more details. With OpenID Connect, this information is either extracted from the claims of the JWT issued as a result of the OpenID Connect authentication flow, or is retrieved from LDAP.
A primary GID must be provided for each user (apart from service tokens for service-to-service access). For federated identity and GitHub deployments, the primary GID is the user’s user private group (see User private groups). For deployments that use a local identity provider, the primary GID must come from either a claim in the OpenID Connect ID token or from LDAP.
See DMTN-225 for more details on the identity information stored for each user and its sources.
COmanage#
COmanage is a web application with associated database and API that manages an organization of users. Information about those users is then published to an LDAP server, which can be queried by Gafaelfawr as needed. COmanage has multiple capabilities, only a few of which will be used by the Science Platform. Its main purposes for the Science Platform are to:
manage the association of users with federated identities;
assign usernames to authenticated users;
determine the eligibility of users for Science Platform access and for roles within that access;
manage group membership, both for groups maintained by Rubin Observatory and for user-managed groups; and
store additional metadata about the user such as email, full name, and institutional affiliation.
CILogon is agnostic to whether a user is registered or has an account in some underlying database. It prompts the user for an identity provider to use, authenticates them, and then provides that identity information to the OpenID Connect relying party (Gafaelfawr). Gafaelfawr, however, only wants to allow access to users who are registered in COmanage, and otherwise ask the user to register so that they can be evaluated and possibly approved for Science Platform access.
To implement this, the Gafaelfawr OpenID Connect integration with COmanage is configured to pull the user’s registered username (what COmanage calls their UID) from COmanage LDAP.
CILogon will find their username by looking up their LDAP entry based on the CILogon opaque identifier assigned to that user from that identity provider (which COmanage stores in a multivalued uid attribute in the person tree in LDAP) and retrieving their username (which COmanage stores in the voPersonApplicationUID attribute).
CILogon then adds that username as the username claim in the JWT provided to Gafaelfawr at the conclusion of the OpenID Connect authentication.
If that claim is missing, the user is not registered, and Gafaelfawr then redirects them to an onboarding flow. Otherwise, Gafaelfawr retrieves group information from LDAP and then uses that to assign scopes to the newly-created session token (see Browser flows).
For the precise details of how COmanage is configured, see SQR-055.
COmanage onboarding#
If the user is not already registered in COmanage, they will be redirected to an onboarding flow in the COmanage web UI. We use the “Self Signup With Approval” flow, one of the standard COmanage enrollment flows, with some modifications detailed in SQR-055. This will use their identity information from CILogon and prompt them for their preferred name, email address, and username. They will be required to confirm that they can receive email at the email address they give. The choice of username is subject to constraints specified in DMTN-225. The user’s COmanage account will then be created in a pending state, and must be approved by an authorized approver before it becomes active and is provisioned in LDAP (and thus allows access to the Science Platform).
We would prefer to treat names as opaque strings, without making any cultural assumptions about the number of components or order of components. Unfortunately, COmanage doesn’t support this configuration and requires representing a name in components. The compromise we reached with this is to allow only given and family name components and only require the given name be set. Users can add middle name in the given name field, suffixes in the family name field, and so forth if they wish. COmanage will then assemble those components into a display name (probably by using western name order), and all other Science Platform components will use only that complete display name if they use a name at all.
The web pages shown during this onboarding flow are controlled by the style information in the lsst-registry-landing project on GitHub.
Approvers are notified via email by COmanage that a new user is awaiting approval. Approval will be based on the institutional affiliation information collected by COmanage from the identity information released by the user’s identity provider via CILogon. Approvers may have to reach out to the prospective user or their institution to gather additional information before deciding whether the user has data rights.
Once the user is approved, they will typically be added automatically to a general users group. (The exact configuration may vary by deployment of the Science Platform.) The approver may want or need to add them to additional groups depending on their intended role.
The user will be notified of their approval via email.
They will then be able to return to the Science Platform deployment and log in, and CILogon will now release their username in the username claim, allowing Gafaelfawr to look up their identity information and group membership in the LDAP server populated by COmanage, assign them scopes, and allow them to continue to the Science Platform.
COmanage user UI#
COmanage provides a web-based user interface to the user. From that interface, they can change their preferred name and email address and review their identity information.
To add another federated identity for the same user, the user can initiate the “Link another account” enrollment flow. They will be prompted to log in again at CILogon, and can pick a different authentication provider. After completing that authentication, the new identity and authentication method will be added to their existing account. All such linked identities can be used interchangeably to authenticate to the same underlying Science Platform account.
If the user no longer intends to use an identity provider, they can unlink it from their account in the UI.
COmanage provides a group management mechanism called COmanage Registry Groups. This allows users to create and manage groups. This group mechanism is used for both user-managed and institution-managed groups. From the COmanage UI, users can change the membership of any group over which they have administrative rights, and can create new user-managed groups.
COmanage administrators (designated by their membership in an internal COmanage group) can edit user identity information of other users via the COmanage UI, and can change any group (including user-managed groups, although normally an administrator will only do that to address some sort of problem or support issue).
COmanage LDAP#
The data stored in COmanage is exported to LDAP in two trees. The person tree holds entries for each Science Platform user. The group tree holds entries for every group (Rubin-managed or user-managed).
During login, and when a Science Platform application requests user identity data, Gafaelfawr retrieves user identity information by looking up the user in the person tree, and retrieves the user’s group membership by searching for all groups that have that user as a member.
A typical person tree entry looks like:
dn: voPersonID=LSST100006,ou=people,o=LSST,o=CO,dc=lsst,dc=org
sn: Allbery
cn: Russ Allbery
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: eduMember
objectClass: voPerson
displayName: Russ Allbery
mail: rra@lsst.org
uid: http://cilogon.org/serverA/users/15423111
uid: http://cilogon.org/serverT/users/40811318
isMemberOf: CO:members:all
isMemberOf: CO:members:active
isMemberOf: CO:admins
isMemberOf: g_science-platform-idf-dev
isMemberOf: g_test-group
voPersonApplicationUID: rra
voPersonID: LSST100006
voPersonSoRID: http://cilogon.org/serverA/users/31388556
voPersonApplicationUID is, as mentioned above, the user’s username.
The uid multivalued attribute holds the unique CILogon identifiers.
voPersonID is an internal unique identifier for that user that’s used only by COmanage.
The user’s preferred full name is in displayName and their preferred email address is in mail.
A typical group tree entry looks like:
dn: cn=g_science-platform-idf-dev,ou=groups,o=LSST,o=CO,dc=lsst,dc=org
cn: g_science-platform-idf-dev
member: voPersonID=LSST100006,ou=people,o=LSST,o=CO,dc=lsst,dc=org
member: voPersonID=LSST100008,ou=people,o=LSST,o=CO,dc=lsst,dc=org
member: voPersonID=LSST100009,ou=people,o=LSST,o=CO,dc=lsst,dc=org
member: voPersonID=LSST100010,ou=people,o=LSST,o=CO,dc=lsst,dc=org
member: voPersonID=LSST100011,ou=people,o=LSST,o=CO,dc=lsst,dc=org
member: voPersonID=LSST100012,ou=people,o=LSST,o=CO,dc=lsst,dc=org
member: voPersonID=LSST100013,ou=people,o=LSST,o=CO,dc=lsst,dc=org
objectClass: groupOfNames
objectClass: eduMember
hasMember: rra
hasMember: adam
hasMember: frossie
hasMember: jsick
hasMember: cbanek
hasMember: afausti
hasMember: simonkrughoff
GitHub#
A Science Platform deployment using GitHub registers Gafaelfawr as an OAuth App. When the user is sent to GitHub to perform an OAuth 2.0 authentication, they are told what information about their account the application is requesting, and are prompted for which organizational information to release. After completion of the OAuth 2.0 authentication flow, Gafaelfawr then retrieves the user’s identity information (full name, email address, and UID) and their team memberships from any of their organizations.
Group membership for Science Platform purposes is synthesized from GitHub team membership.
Each team membership that an authenticated user has on GitHub (and releases through the GitHub OAuth authentication) will be mapped to a group.
The name of the group will be <organization>-<team-slug> where <organization> is the login attribute (forced to lowercase) of the organization containing the team and <team-slug> is the slug attribute of the team.
These values are retrieved through GitHub’s /user/teams API route.
The slug attribute is constructed by GitHub based on the name of the team, removing case differences and replacing special characters like space with a dash.
Some software may limit the length of group names to 32 characters, and forming group names this way may result in long names if both the organization and team name is long. Therefore, if the group name formed as above is longer than 32 characters, it will be truncated and made unique. The full group name will be hashed (with SHA-256) and truncated at 25 characters, and then a dash and the first six characters of the URL-safe-base64-encoded hash will be appended.
The id attribute for each team will be used as the GID of the corresponding group.
User private groups#
For federated identity and GitHub deployments, every user is automatically also a member (and the only member) of a group whose name matches the username and whose GID matches the user’s UID. This is called a user private group. This allows Science Platform services to use the user’s group membership for authorization decisions without separately tracking authorization rules by username, since access to a specific user can be done by granting access to that user’s user private group (which will contain only that one member). The GID of this group is also the user’s primary GID and should be their default group for services with POSIX file system access, such as the Notebook Aspect.
For GitHub deployments, the user’s account ID (used for their UID) is also used for the GID for their user private group. This risks a conflict, since the user account ID space is not distinct from the team ID space, which is used for the GIDs of all other groups. If a user’s account ID happens to be the same number as a team ID, members of that team could have access to the user’s group-accessible files, or the user may incorrectly have access to that team’s files. We are currently ignoring this potential conflict on the grounds that, given the sizes of the spaces involved and the small number of users on GitHub deployments, it’s unlikely to happen in practice.
Deployments that use OpenID Connect with a local identity provider may or may not provide user private groups. This will depend on the details of GID assignment and group management in the local identity provider. If they do not, access control by username may not work, since services may implement that access control by checking only group membership.
Authentication flows#
This section assumes the COmanage account for the user already exists if COmanage is in use. If it does not, see COmanage onboarding.
See the Gafaelfawr documentation for specific details on the ingress-nginx annotations used to protect services and the HTTP headers that are set and available to be passed down to the service after successful authentication.
The ingress annotations should be managed by creating a GafaelfawrIngress custom resource (see Ingresses) rather than an Ingress resource.
The gafaelfawr-operator pod will then create the corresponding Ingress resource.
Browser flows#
If the user visits a Science Platform page intended for a web browser (as opposed to APIs) and is not already authenticated (either missing a cookie or having an expired cookie), they will be sent to an identity provider to authenticate.
Generic authentication flow#
Here is a diagram of the generic login flow.
sequenceDiagram
browser->>+ingress: service URL
ingress->>+Gafaelfawr: auth subrequest
Gafaelfawr-->>-ingress: 401
ingress-->>-browser: redirect to /login
browser->>+ingress: /login
ingress->>+Gafaelfawr: /login
Gafaelfawr-->>-ingress: redirect to provider
ingress-->>-browser: redirect to provider
browser->>+provider: authenticate
provider-->>-browser: redirect to /login
browser->>+ingress: /login
ingress->>+Gafaelfawr: /login
Gafaelfawr->>+provider: get token
provider-->>-Gafaelfawr: token
Gafaelfawr-->>-ingress: redirect to service
ingress-->>-browser: redirect to service
browser->>+ingress: service URL
ingress->>+Gafaelfawr: auth subrequest
Gafaelfawr-->>-ingress: 200
ingress->>+service: service URL
service-->>-ingress: response
ingress-->>-browser: response
Fig. 1 Generic browser authentication flow#
This diagram omits the possible request from Gafaelfawr to an LDAP server for additional user metadata to avoid making it even smaller than it already is.
Here are the generic steps of a browser authentication flow. The details of steps 5 and 6 vary depending on the authentication provider, as discussed in greater depth below.
The user attempts to access a Science Platform web page that requires authentication.
The Gafaelfawr
/authroute receives the headers of the original request. No token is present in anAuthorizationheader, nor is there an authentication session cookie. The/authroute therefore returns an HTTP 401 error.ingress-nginx determines from its
nginx.ingress.kubernetes.io/auth-signinannotation that the user should be redirected to the/loginroute with the original URL included in theX-Auth-Request-Redirectheader.The Gafaelfawr
/loginroute sets a session cookie containing a randomly-generatedstateparameter. It also includes the return URL in that session cookie. It then returns a redirect to the authentication provider that contains thestatestring plus other required information for the authentication request.The user interacts with the authentication provider to prove their identity, which eventually results in a redirect back to the
/loginroute. That return request includes an authorization code and the originalstatestring, as well as possibly other information.The
/loginroute requires thestatecode match the value from the user’s session cookie. It then extracts the authorization code and redeems it for a token from the authentication provider. Gafaelfawr may then validate that token and may use it to get more information about the user, depending on the identity provider as discussed below.Based on the user’s identity data, the
/loginroute creates a new session token and stores the associated data in the Gafaelfawr token store. If Firestore is used for UIDs, the UID for this username is retrieved from Firestore and stored with the token. It then stores that token in the user’s session cookie. Finally, it redirects the user back to the original URL.When the user requests the original URL, this results in another authentication subrequest to the
/authroute. This time, the/authroute finds the session cookie and extracts the token from that cookie. It retrieves the token details from the token store and decrypts and verifies it. It then checks the scope information of that token against the requested authentication scope given as ascopeparameter to the/authroute. If the requested scope or scopes are not satisfied, it returns a 403 error. If LDAP is configured, user metadata such as email address is retrieved from LDAP.The metadata, either from the data stored with the token or from LDAP, is added to additional response headers. Gafaelfawr also copies the
AuthorizationandCookieheaders from the incoming request to the reply with any Gafaelfawr tokens or cookies removed. Gafaelfawr then returns 200 with those response headers, and NGINX then proxies the request to the protected application and user interaction continues as normal. The response headers from Gafaelfawr —Authorization,Cookie, and the additional metadata headers — are added to the request sent to the protected application, replacing the headers in the original request. The filtering of theAuthorizationandCookieheaders is to prevent credential leakage to services. See SQR-051 for more details.
Of special security note is the state parameter validation.
During initial authentication, Gafaelfawr sends a state parameter to the OAuth 2.0 or OpenID Connect authentication provider and also stores that parameter in the session cookie.
On return from authentication, the state parameter returned by the authentication provider is compared to the value in the session cookie and the authentication is rejected if they do not match.
This protects against session fixation (an attacker tricking a user into authenticating as the attacker instead of the user, thus giving the attacker access to data subsequently uploaded to the user).
The state value is a 128-bit random value generated using os.urandom().
CILogon#
Here is the CILogon authorization flow in detail.
sequenceDiagram
browser->>+Gafaelfawr: /login
Gafaelfawr-->>-browser: redirect to CILogon
browser->>+CILogon: auth request
CILogon-->>-browser: redirect to provider
browser->>+provider: authenticate
provider-->>-browser: redirect to CILogon
browser->>+CILogon: w/authorization code
CILogon->>+provider: get ID token
provider-->>-CILogon: JWT
CILogon-->>-browser: redirect to /login
browser->>+Gafaelfawr: /login
Gafaelfawr->>+CILogon: get ID token
CILogon-->>-Gafaelfawr: JWT
Gafaelfawr->>+CILogon: get OIDC config
CILogon-->>-Gafaelfawr: config
Gafaelfawr->>+LDAP: get user data
LDAP-->>-Gafaelfawr: user data
Gafaelfawr-->>-browser: redirect to service
Fig. 2 CILogon browser authentication flow#
This diagram omits the ingress, the initial unauthenticated redirect to /login, and the service to which the user is sent once the login process is complete.
All of those steps happen identically to the generic browser flow.
The following specific steps happen during step 5 of the generic browser flow.
CILogon prompts the user for which identity provider to use, unless the user has previously chosen an identity provider and told CILogon to remember that selection.
CILogon redirects the user to that identity provider. That identity provider does whatever it chooses to do to authenticate the user and redirects the user back to CILogon. CILogon then takes whatever steps are required to complete the authentication using whatever protocol that identity provider uses, whether it’s SAML, OAuth 2.0, OpenID Connect, or something else.
The following specific steps happen during step 6 of the generic browser flow, in addition to the state validation and code redemption:
Gafaelfawr retrieves the OpenID Connect configuration information for CILogon and checks the signature on the JWT identity token.
Gafaelfawr extracts the user’s username from the
usernameclaim of the identity token. If that claim is missing, Gafaelfawr redirects the user to the enrollment flow at COmanage, which aborts the user’s attempt to access whatever web page they were trying to visit.Gafaelfawr retrieves the user’s UID from Firestore, assigning a new UID if necessary if that username had not been seen before.
Gafaelfawr retrieves the user’s group membership from LDAP using the
usernameas the search key.
Subsequently, whenever Gafaelfawr receives an authentication subrequest to the /auth route, it retrieves the user’s identity information (name from displayName, email from mail) and group membership from LDAP.
For each group, the GID for that group is retrieved from Firestore, and a new GID is assigned if that group has not been seen before.
That data is then returned in HTTP headers that ingress-nginx includes in the request to the Science Platform service being accessed.
Similarly, Gafaelfawr retrieves the user’s identity information and group membership from LDAP and Firestore whenever it receives a request for the user information associated with a token.
(In practice, both the LDAP and Firestore data is usually cached. See Caching for more information.)
Note that, in the CILogon and COmanage case, user identity data is not stored with the token. Gafaelfawr retrieves it on the fly whenever it is needed (possibly via a cache). Changes to COmanage are therefore reflected immediately in the Science Platform (after the expiration of any cache entries).
GitHub#
Here is the GitHub authentication flow in detail.
sequenceDiagram
browser->>+Gafaelfawr: /login
Gafaelfawr-->>-browser: redirect to GitHub
browser->>+GitHub: authenticate
GitHub-->>-browser: redirect to /login
browser->>+Gafaelfawr: /login
Gafaelfawr->>+GitHub: get access token
GitHub-->>-Gafaelfawr: access token
Gafaelfawr->>+GitHub: get user info
GitHub-->>-Gafaelfawr: user info
Gafaelfawr->>+GitHub: get user email
GitHub-->>-Gafaelfawr: email info
Gafaelfawr->>+GitHub: get user teams
GitHub-->>-Gafaelfawr: teams info
Gafaelfawr-->>-browser: redirect to service
Fig. 3 GitHub browser authentication flow#
This diagram omits the ingress, the initial unauthenticated redirect to /login, and the service to which the user is sent once the login process is complete.
All of those steps happen identically to the generic browser flow.
The following specific steps happen during step 5 of the generic browser flow.
GitHub prompts the user for their authentication credentials if they’re not already authenticated.
If the user has not previously authorized the OAuth App for this Science Platform deployment, the user is prompted to confirm to GitHub that it’s okay to release their identity information and organization membership to Gafaelfawr.
The following specific steps happen during step 6 of the generic browser flow, in addition to the state validation and code redemption.
Using the authentication token received after redeeming the code, the user’s full name and
id(used as their UID) is retrieved from the GitHub/userroute.Using the same token, the user’s primary email address is retrieved from the GitHub
/usr/emailsroute.Using the same token, the user’s team memberships (where Gafaelfawr is authorized to access them) are retrieved from the GitHub
/user/teamsroute.The token is then stored in the user’s encrypted cookie as their GitHub session token.
The user’s identity data retrieved from GitHub is stored with the session token and inherited by any other child tokens of the session token, or any user tokens created using that session token. Changes on the GitHub side are not reflected in the Science Platform until the user logs out and logs back in, at which point their information is retrieved fresh from GitHub and stored in the new session token and any of its subsequent child tokens or user tokens.
When the user logs out, the GitHub session token is used to explicitly revoke the user’s OAuth App authorization at GitHub. This forces the user to return to the OAuth App authorization screen when logging back in, which in turn will cause GitHub to release any new or changed organization information. Without the explicit revocation, GitHub reuses the prior authorization with the organization and team data current at that time and doesn’t provide data from new organizations. See Cookie data for more information.
OpenID Connect#
Here is the OpenID Connect authentication flow in detail.
sequenceDiagram
browser->>+Gafaelfawr: /login
Gafaelfawr-->>-browser: redirect to OIDC
browser->>+OIDC: authenticate
OIDC-->>-browser: redirect to /login
browser->>+Gafaelfawr: /login
Gafaelfawr->>+OIDC: get ID token
OIDC-->>-Gafaelfawr: JWT
Gafaelfawr->>+OIDC: get OIDC config
OIDC-->>-Gafaelfawr: config
Gafaelfawr->>+LDAP: get user data
LDAP-->>-Gafaelfawr: user data
Gafaelfawr-->>-browser: redirect to service
Fig. 4 GitHub browser authentication flow#
This diagram omits the ingress, the initial unauthenticated redirect to /login, and the service to which the user is sent once the login process is complete.
All of those steps happen identically to the generic browser flow.
This diagram assumes identity data is stored in LDAP.
The following specific steps happen during step 6 of the generic browser flow.
Gafaelfawr retrieves the OpenID Connect configuration information for the OpenID Connect provider and checks the signature on the JWT identity token.
Gafaelfawr extracts the user’s username from a claim of the identity token. (This is configured per OpenID Connect provider.)
If LDAP is not configured, Gafaelfawr extracts the user’s identity information from the JWT to store it with the session token.
If LDAP is configured, Gafaelfawr retrieves the user’s group membership from LDAP using the username as a key.
If LDAP is configured, whenever Gafaelfawr receives an authentication subrequest to the /auth route, it retrieves the user’s identity information and group membership from LDAP.
That data is then returned in HTTP headers that ingress-nginx includes in the request to the Science Platform service being accessed.
Similarly, if LDAP is configured, Gafaelfawr retrieves the user’s identity information and group membership from LDAP whenever it receives a request for the user information associated with a token.
(In practice, the LDAP data is usually cached. See Caching for more information.)
If LDAP is in use, user identity data is not stored with the token. Gafaelfawr retrieves it on the fly whenever it is needed (possibly via a cache). Changes in LDAP are therefore reflected immediately in the Science Platform (after the expiration of any cache entries).
If instead the user’s identity information comes from the JWT issued by the OpenID Connect authentication process, that data is stored with the token and inherited by any other child tokens of the session token, or any user tokens created using that session token, similar to how data from GitHub is handled.
Group membership obtained from the OpenID Connect token may or may not include GIDs for each group. Missing GIDs are not considered an error, and scopes will still be calculated correctly for groups without GIDs, but no GIDs for groups will be provided to other services. This may prevent using groups for access control for services that use a POSIX file system, such as the Notebook Aspect.
Logout flow#
The user may go to /logout at any time to revoke their current session.
Their session token will be revoked, which will also revoke all child tokens, so any services still performing actions on the behalf of that user from that session will immediately have their credentials revoked.
As discussed in GitHub, this will also revoke their GitHub OAuth App authorization in Science Platform deployments using GitHub for identity.
The /logout route takes an rd parameter specifying the URL to which to direct the user after logout.
If it is not set, a default value configured for that Science Platform deployment (usually the top-level page) will be used instead.
Redirect restrictions#
The /login and /logout routes redirect the user after processing.
The URL to which to redirect the user may be specified as a GET parameter or, in the case of /login, an HTTP header that is normally set by ingress-nginx.
To protect against open redirects, the specified redirect URL must be on the same host as the host portion of the incoming request for the /login or /logout route.
(This is expected to change in the future when the more complex domain scheme proposed in DMTN-193 is adopted.)
X-Forwarded-Host headers (expected to be set by ingress-nginx) are trusted for the purposes of determining the host portion of the request.
Forwarded appears not to be supported by the NGINX ingress at present and therefore is not used.
For more details on the required configuration to ensure that X-Forwarded-* headers are correctly set by ingres-nginx, see Client IP addresses.
Uauthenticated JavaScript#
Normally, an authenticated user results in Gafaelfawr returning a 401 response, which in turn tells ingress-nginx to replace this response with a redirect the user to the login route.
This approach to login handling can cause problems when combined with expiring sessions and web pages with JavaScript that makes background requests. If the user had previously authenticated and has a web page with active JavaScript open, and then their authentication credentials expire, the page JavaScript may continue to make requests. If those requests result in 401 errors and thus redirects to the login page, JavaScript will attempt to follow that redirect and get back an HTML page that it doesn’t know what to do with. Depending on the JavaScript, this may trigger an error condition that causes it to repeatedly retry. Worse, the login action normally triggers a further redirect to the identity provider, which in turn may trigger further redirects and relatively expensive operations such as creating a login session. On a page with very active JavaScript and a deployment with relatively expensive login handling, this can create an inadvertant denial of service attack on the identity provider.
To avoid this, if Gafaelfawr sees a request from an unauthenticated user that contains the HTTP header X-Requested-With: XMLHttpRequest, it returns a 403 error rather than a 401 error.
This returns an immediate permission denied error that does not trigger the redirect handling in ingress-nginx.
The presence of this header indicates an AJAX request, which in turn means that the request is not under full control of the browser window.
The JavaScript call will still fail, but with a more straightforward error message and without creating spurious load on the identity provider.
When the user reloads the page, the browser will send a regular request without that header and receive the normal redirect.
Checking for this header does not catch all requests that are pointless to redirect (image and CSS requests, for instance), and not all AJAX requests will send the header, but in practice it seems to catch the worst cases.
Token flows#
All token authentication flows are similar, and much simpler.
The client puts the token in an Authorization header, either with the bearer keyword (preferred) as an RFC 6750 bearer token, or as either the username or password of RFC 7617 HTTP Basic Authentication.
Whichever Basic Authentication field is not a token is ignored.
If both the usenrame and password fields of a Basic Authentication header are tokens, they must be identical.
Gafaelfawr returns a 401 response code from the auth subrequest if no Authorization header is present, and a 403 response code if credentials are provided but not valid.
In both cases, this is accompanied by a WWW-Authenticate challenge.
By default, this is an RFC 6750 bearer token challenge, but Gafaelfawr can be configured to return a RFC 7617 HTTP Basic Authentication challenge instead (via a parameter to the /auth route, when it is configured in the Ingress as the auth subrequest handler).
Currently, however, the WWW-Authenticate header of a 403 error is not correctly conveyed to the client due to limitations in the NGINX configuration.
Gafaelfawr returns a 200 response code if the credentials are valid, which tells ingress-nginx to pass the request (possibly with additional headers) to the protected service.
The behavior of redirecting the user to log in if they are not authenticated is implemented in ingress-nginx by configuring its response to a 401 error from the auth subrequest.
For API services that are not used by browsers, ingress-nginx should not be configured with the nginx.ingress.kubernetes.io/auth-signin annotation (the config.loginRedirect setting of a GafaelfawrIngress).
In this case, it will return the 401 challenge to the client instead of redirecting.
When authenticating a request with a token, Gafaelfawr does not care what type of token is presented. It may be a user, notebook, internal, or service token; all of them are handled the same way. The same is true of oidc tokens, although at present oidc tokens are never issued with scopes and therefore generally cannot be used to authenticate to anything other than Gafaelfawr itself.
Service tokens, used for service-to-service API calls unrelated to a specific user request, are managed as Kubernetes secrets via a Kubernetes custom resource. For more details, see Service tokens.
Service-to-service authentication#
There are some cases in a microservice architecture where it is desirable for a service to make calls to a lower-level service on behalf of the user, but to not allow the user to make calls to the lower-level service directly. One example is the UWS storage service proposed in SQR-096.
Gafaelfawr implements this as a token authentication flow. The higher-level service requests a delegated token with appropriate scopes to call the lower-level service, as normal. The lower-level service then uses a Gafaelfawr-protected ingress that limits access to a specific named list of other services.
In this mode, Gafaelfawr will reject authentication from any token other than an internal token. When presented with an internal token, it will retrieve the name of the service to which that internal token was issued and check that it is on the allow list of services permitted to access the lower-level service. If the user attempts to authenticate directly, they will be using a token type other than internal and their token will not be associated with a service, so their access will be denied.
In order for this security model to work, users must not have the ability to create or access internal tokens created for services. This implies that the route intended for ingress-nginx auth subrequests not be exposed to the user. See Ingress integration for more details on how that’s accomplished.
Reuse of notebook and internal tokens#
A user often makes many requests to a service over a short period of time, particularly when using a browser and requesting images, JavaScript, icons, and similar resources. If that service needs delegated tokens (notebook or internal tokens), a naive approach would create a plethora of child tokens, causing significant performance issues. Gafaelfawr therefore reuses notebook and internal tokens where possible.
The criteria for reusing a notebook token is:
Same parent token
Parent token expiration has not changed
Parent token’s scopes are still a superset of the child token’s scopes
Child token is still valid
Child token has a remaining lifetime of at least half the normal token lifetime (or the lifetime of the parent token, whichever is shorter)
Child token has a remaining lifetime of at least as long as the requested minimum remaining lifetime, if one was set.
To reuse an internal token, it must meet the same criteria, plus:
Same requested child token service
Same requested child token scopes
If a notebook or internal token already exists that meet these criteria, that token is returned as the token to delegate to the service, rather than creating a new token.
Notebook and internal tokens are also cached to avoid the SQL and Redis queries required to find a token that can be reused. See Caching for more information.
Per-user ingresses#
In some cases, there should be a one-to-one mapping between a user and an ingress, or between a user and the domain name of that ingress. Examples here include per-user WebDAV file servers, where the ingress should only permit access by the user who owns the file server; or the ingress for user JupyterLab instances running on per-user subdomains, where the ingress should only allow access to the user whose identity matches the name of the subdomain.
Gafaelfawr supports both of these configurations with configuration options in the GafaelfawrIngress Kubernetes resource (see Ingresses).
A given ingress can be restricted to a specific user, or can be configured to only accept requests from a username that matches the leftmost component of the hostname of the request.
OPTIONS requests#
HTTP OPTIONS requests are used for CORS preflight requests from web browsers to detect if JavaScript-driven cross-site requests are allowed.
When used for CORS preflight, OPTIONS requests do not contain user authentication credentials, and therefore require special handling.
Gafaelfawr has to authorize OPTIONS requests like any other HTTP request to the Science Platform through a protected ingress.
It uses that opportunity to impose a uniform CORS policy for all protected services: CORS preflight requests must come from an origin within that instance of the Science Platform (either its parent domain or, if subdomain support is enabled, child domains).
All CORS preflight requests from outside the Science Platform are rejected without sending them to the protected service.
CORS preflight requests that do come from inside the Science Platform are passed to the protected service. The service then has to choose how to respond, so CORS preflight requests are only authorized if both Gafaelfawr believes they’re from within the Science Platform and if the underlying service approves them.
Non-CORS OPTIONS requests are rejected with a 404 error by default, but they are required for some protocols such as WebDAV.
Gafaelfawr therefore has an option to allow them for a given ingress, in which case any OPTIONS request that is not a CORS preflight request will be passed to the backend unmodified, even if it does not contain authentication credentials.
OpenID Connect flow#
Some services deployed on the Science Platform (such as Chronograf) want to do their own authentication using an upstream OpenID Connect provider and don’t have a mechanism to rely on authentication performed by ingress-nginx. Specific Science Platform installations may also be used as an authentication and authorization service for IDACs. To support those use cases, Gafaelfawr can also serve as a simple OpenID Connect provider.
Here is the flow using Gafaelfawr’s OpenID Connect provider.
sequenceDiagram
browser->>+service: /service
service-->>-browser: redirect to /auth/openid/login
browser->>+Gafaelfawr: /auth/openid/login
Gafaelfawr-->>-browser: redirect to /service/login
browser->>+service: /service/login
service->>+Gafaelfawr: /auth/openid/token
Gafaelfawr-->>-service: JWT
service->>+Gafaelfawr: /auth/openid/userinfo
Gafaelfawr-->>-service: user metadata
service-->>-browser: redirect to /service
browser->>+service: /service
service-->>-browser: page contents
Fig. 5 Gafaelfawr OpenID Connect flow#
This diagram assumes the user is already authenticated to Gafaelfawr and therefore omits the flow to the external identity provider (see Browser flows). It also omits the ingress layer and any calls from Gafaelfawr to LDAP to get the user’s metadata.
In detail:
The user goes to an service that uses Gafaelfawr as an OpenID Connect authentication provider.
The service redirects the user to
/auth/openid/loginwith some additional parameters in the URL including the registered client ID, an opaque state parameter, and the list of requested OpenID Connect scopes.If the user is not already authenticated, Gafaelfawr authenticates the user using the normal browser flow, sending the user back to the same
/auth/openid/loginURL once that authentication has completed.Gafaelfawr validates the login request and then redirects the user back to the protected service, including an authorization code in the URL.
The protected service presents that authorization code to
/auth/openid/tokenalong with its authentication credentials.Gafaelfawr validates that code and returns a JWT representing the user to the protected service. It also returns, as the access token, a Gafaelfawr token of type
oidcwith no scopes. The authorization code is then invalidated and cannot be used again.The protected service should validate the signature on the JWT by retrieving metadata about the signing key from
/.well-known/openid-configurationand/.well-known/jwks.json, which are also served by Gafaelfawr. The protected service can then read information directly from the JWT claims.The protected service optionally authenticates as the user to
/auth/userinfo, using the access token as a bearer token, and retrieve metadata about the authenticated user. This is an OpenID Connect Userinfo endpoint and follows the rules in that specification. Gafaelfawr currently returns all available claims from any scope rather than restricting the list of claims to those requestsed by the client, and does not support claim restrictions on the userinfo response. This endpoint accepts tokens of typeinternalas well asoidcfor reasons explained in CADC services.
In order to use the OpenID Connect authentication flow, a service has to pre-register a client ID, secret, and return URL.
The list of valid client IDs, secrets, and return URLs for a given deployment are stored as a JSON blob in the Gafaelfawr secret.
Gafaelfawr will only allow authentication if the redirect_uri parameter matches the registered return URL for the requesting client.
The OpenID Connect relying party must then present that same client ID, secret, and redirect_uri as part of the request to redeem a code for a token.
This is the OpenID Connect authorization code flow. See the OpenID Connect specification for more information. This implementation has the following protocol limitations:
Only the
authorization_codegrant type is supported, and only thecoderesponse type is supported.Only the
client_secret_posttoken authentication method is supported.Only
GETrequests to the authorization endpoint are supported.Most optional features of the OpenID Connect protocol are not yet supported.
Scopes and claim requests or restrictions are not supported in the userinfo endpoint.
Gafaelfawr supports a custom rubin OpenID Connect scope that, if requested, adds the data_rights claim to the ID token with a space-separated list of data releases to which the user has access.
This list is generated based on the user’s group membership and a mapping from groups to data releases that is manually maintained in the Gafaelfawr configuration.
The authorization codes Gafaelfawr returns as part of this OpenID Connect authentication flow are stored in Redis.
The JWTs issued by the OpenID Connect authentication are unrelated to the tokens used elsewhere in the Science Platform and cannot be used to authenticate to services protected by the normal token and browser authentication flows.
Gafaelfawr always uses the RS256 algorithm for JWTs, which signs the token (but does not encrypt it) with a 2048-bit RSA key.
JWT signing and validation is done using PyJWT.
The public key used for the JWT signature is published at the standard /.well-known/openid-configuration URL defined in the OpenID Connect Discovery 1.0 specification.
Gafaelfawr does no scope or other authorization checks when doing OpenID Connect authentication. All checks are left to the application that initiates the authentication.
For more details about the OpenID Connect authentication flow and its intended use by IDACs, see DMTN-253.
Specific services#
The general pattern for protecting a service with authentication and access control is configure its Ingress resources with the necessary ingress-nginx annotations and then let Gafaelfawr do the work.
If the service needs information about the user, it obtains that from the X-Auth-Request-* headers that are set by Gafaelfawr via ingress-nginx, or by requesting a delegated token and then using the token API to retrieve details about the token or the user’s identity information.
If the service requests a delegated token, that token will be present in the X-Auth-Request-Token header of the request as passed to the service.
Optionally, it can instead be put in the Authorization header as a bearer token.
Some Science Platform services require additional special attention.
Notebook Aspect#
JupyterHub supports an external authentication provider, but then turns that authentication into an internal session that is used to authenticate and authorize subsequent actions by the user.
This session is normally represented by a cookie JupyterHub sets in the browser.
JupyterHub also supports bearer tokens, with the wrinkle that JupyterHub requires using the token keyword instead of bearer in the Authorization header.
JupyterHub then acts as an OAuth authentication provider to authenticate the user to any spawned lab. The lab obtains an OAuth token for the user from the hub and uses that for subsequent authentication to the lab.
The JupyterHub authentication session can include state, which is stored in the JupyterHub session database. In the current Science Platform implementation, that session database is stored in a PostgreSQL server also run inside the same Kubernetes cluster, protected by password authentication with a password injected into the JupyterHub pod. The data stored in the authentication session is additionally encrypted with a key known only to JupyterHub.
The ingress for JupyterHub is configured to require Gafaelfawr authentication and access control for all JupyterHub and lab URLs. Therefore, regardless of what JupyterHub and the lab think is the state of the user’s authentication, the request is not allowed to reach them unless the user is already authenticated, and any redirects to the upstream identity provider are handled before JupyterHub ever receives a request. The user is also automatically redirected to the upstream identity provider to reauthenticate if their credentials expire while using JupyterHub. The ingress configuration requests a delegated notebook token.
Gafaelfawr is then integrated into JupyterHub with a custom JupyterHub authentication provider.
That provider runs inside the context of a request to JupyterHub that requires authentication.
It registers a custom route (/gafaelfawr/login in the Hub’s route namespace) and returns it as a login URL.
That custom route reads the headers from the incoming request, which are set by Gafaelfawr, to find the delegated notebook token, and makes an API call to Gafaelfawr using that token for authentication to obtain the user’s identity information.
That identity information along with the token are then stored as the JupyterHub authentication session state.
Information from the authentication session state is used when spawning a user lab to control the user’s UID, GID, groups, and other information required by the lab, and the notebook token is injected into the lab so that it will be available to the user.
sequenceDiagram
participant browser
participant Gafaelfawr
participant JupyterHub
browser->>+JupyterHub: request spawn page
JupyterHub-->>-browser: redirect to /nb/gafaelfawr/login
browser->>+JupyterHub: /nb/gafaelfawr/login
JupyterHub->>+Gafaelfawr: /auth/api/v1/user-info
Gafaelfawr-->>-JupyterHub: user metadata
JupyterHub-->>-browser: spawn page
browser->>+JupyterHub: spawn request
create participant lab
JupyterHub->>lab: create lab
JupyterHub->>+lab: wait for startup
lab-->>-JupyterHub: finish startup
JupyterHub-->>-browser: redirect to lab
browser->>+lab: request UI
lab->>+JupyterHub: OAuth authentication
JupyterHub-->>-lab: OAuth information
lab-->>-browser: lab UI
Fig. 6 JupyterHub and lab authentication flow#
This diagram assumes the user is already authenticated to Gafaelfawr and therefore omits the flow to the external identity provider (see Browser flows). It also omits the ingress and auth subrequests to Gafaelfawr and the JupyterHub proxy server to try to keep the diagram from being too small to read.
The lab itself is spawned using the UID and primary GID of the user, so that any accesses to mounted POSIX file systems are accessed as the identity of the user. The GIDs of the user’s other groups are added as supplemental groups for the lab process. Note that if NFS is used as the underlying POSIX file system, it may impose a limit on the maximum number of supported supplemental groups.
Because JupyterHub has its own authentication session that has to be linked to the Gafaelfawr authentication session, there are a few wrinkles here that require special attention.
When the user reauthenticates (because, for example, their credentials have expired), their JupyterHub session state needs to be refreshed even if JupyterHub thinks their existing session is still valid. Otherwise, JupyterHub will hold on to the old token and continue injecting it into labs, where it won’t work and cause problems for the user. JupyterHub is therefore configured to force an authentication refresh before spawning a lab (which is when the token is injected), and the authentication refresh checks the delegated token provided in the request headers to see if it’s the same token stored in the authentication state. If it is not, the authentication state is refreshed from the headers of the current request.
The user’s lab may make calls to JupyterHub on the user’s behalf. Since the lab doesn’t know anything about the Gafaelfawr token, those calls are authenticated using the lab’s internal credentials. These must not be rejected by the authentication refresh logic, or the lab will not be allowed to talk to JupyterHub.
Since all external JupyterHub routes are protected by Gafaelfawr and configured to provide a notebook token, the refresh header can check for the existence of an
X-Auth-Request-Tokenheader set by Gafaelfawr. If that header is not present, the refresh logic assumes that the request is internal and defers to JupyterHub’s own authentication checks without also applying the Gafaelfawr authentication integration.
Note that this implementation approach depends on Gafaelfawr reusing an existing notebook token if one already exists. Without that caching, there would be unnecessary churn of the JupyterHub authentication state.
The notebook token is only injected into the lab when the lab is spawned, so it’s possible for the token in a long-running lab to expire. If the user’s overall Gafaelfawr session has expired, they will be forced to reauthenticate and their JupyterHub authentication state will then be updated via JupyterHub’s authentication refresh, but the new stored token won’t propagate automatically to the lab. To address this, JupyterHub requests a minimum remaining lifetime for the delegated notebook token, ensuring that any freshly-spawned lab has a minimum lifetime for its saved credentials. The lab is then configured to have a maximum age matching that minimum lifetime, so by the time the token would expire the lab is automatically shut down by JupyterHub and the user is forced to spawn a new one with fresh credentials.
For a production deployment, JupyterHub should be configured to use separate subdomains for every user in conjunction with a wildcard TLS certificate and ingress. This ensures that each user is isolated from all other users on their own JavaScript origin.
Portal Aspect#
Similar to the Notebook Aspect, the Portal Aspect needs to make API calls on behalf of the user (most notably to the TAP and image API services). Unlike the Notebook Aspect, the Portal Aspect uses a regular internal token with appropriate scopes for this.
The Portal Aspect uses GafaelfawrIngress custom resources to define its ingresses.
There are two separate ingresses, since the admin API requires different scopes than the user-facing service.
In the Science-Platform-specific modifications to Firefly, the software used to create the Portal Aspect, that internal token is extracted from the X-Auth-Request-Token header and sent when appropriate in requests to other services.
Since the Portal Aspect supports using other public TAP and image services in addition to the ones local to the Science Platform deployment in which it’s running, it has to know when to send this token in an Authorization header and when to omit it.
(We don’t want to send the user’s token to third-party services, since that’s a breach of the user’s credentials.)
Currently, this is done via a whitelist of domains in the Science Platform deployment configuration.
The Portal Aspect includes the token in all requests to those domains.
The Portal Aspect wants several scopes for its delegated token so that it can perform operations on the user’s behalf, but it is still usable without those scopes.
It therefore takes advantage of Gafaelfawr’s support for requesting delegated scopes that may or may not be available.
If the user’s authenticating token has the scopes it prefers, it gets an internal token with those scopes; otherwise, it gets an internal token with whatever subset of the scopes the user has, but the authentication still succeeds as long as the user has exec:portal access (the scope used to control all access to the Portal Aspect).
CADC services#
IVOA services maintained by the Canadian Astronomy Data Center (CADC) use a standard authentication system that presents a token to a user information endpoint and expects a JSON object of OpenID Connect claims in response.
The username of the authenticated user is retrieved from the preferred_username key.
This authentication system assumes that user information endpoint is an OpenID Connect Userinfo endpoint, and therefore it queries the /.well-known/openid-configuration route and uses the value of userinfo_endpoint to vind that endpoint.
It doesn’t, however, use a full OpenID Connect authentication workflow.
It just presents whatever token it receives in the Authorization header to that endpoint and expects to get results in the format of an OpenID Connect Userinfo response.
To put those services behind Gafaelfawr, we configure them to request a delegated token with no scopes and tell Gafaelfawr to put the delegated token as a bearer token in an Authorization header intead of X-Auth-Request-Token.
Then, we configure the CADC service with the base URL of the Science Platform as its “OpenID Connect provider.”
Finally, we enable the Gafaelfawr OpenID Connect server so that the /.well-known/openid-configuration and Userinfo endpoints are enabled.
Gafaelfawr accepts token types of either oidc or internal at its OpenID Connect Userinfo endpoint, so when the CADC code presents an internal token there, it responds with an OpenID Connect Userinfo response, including preferred_username.
This satisfies the needs of the CADC code.
This approach is a little awkward since it requires enabling the OpenID Connect server even if it is not used directly as an OpenID Connect identity provider, and it results in CADC applications relying on OpenID Connect metadata and presenting a token to the Userinfo endpoint that has nothing to do with OpenID Connect. But it seems to work well in practice and has the huge advantage of not requiring any modifications or special configuration of the CADC code.
Ingress integration#
Gafaelfawr runs as an auth subrequest handler for ingress-nginx, configured via annotations on the Ingress Kubernetes resource.
(See Ingresses for more details about how that is managed.)
For each (uncached, see NGINX caching) icoming request, NGINX makes a subrequest to Gafaelfawr to determine whether to allow that request and to retrieve headers to add to the request.
In order to securely support service-to-service authentication flows (see Service-to-service authentication), the route used by the ingress for auth subrequests must not be accessible to users. Otherwise, the user could ask that route directly for an internal token for an arbitrary service and bypass service-only restrictions on ingresses.
This is done in Gafaelfawr by ensuring the two routes used only by the ingress, /ingress/auth and /ingress/anonymous, are not exposed by the Gafaelfawr Kubernetes Ingress resources.
These routes therefore can only be accessed by connecting to the Kubernetes Gafaelfawr Service directly, which in turn is restricted to the ingress-nginx pod by NetworkPolicy configuration (see Network policy).
In other words, a typical annotation added to an Ingress resource generated by Gafaelfawr will look like:
nginx.ingress.kubernetes.io/auth-signin: https://data-dev.lsst.cloud/login
nginx.ingress.kubernetes.io/auth-url: >-
http://gafaelfawr.gafaelfawr.svc.cluster.local:8080/ingress/auth?scope=exec%3Aadmin
The sign-in URL, to which brower users will be redirected if not authenticated, uses the normal public URL of the Science Platform deployment.
The auth subrequest URL, used only by the ingress, uses the internal Gafaelfawr Service address and the private /ingress/auth route.
Gafaelfawr by default assumes that the domain of the cluster is cluster.local, the Kubernetes default.
Unfortunately, this can be configured in Kubernetes but is not exposed to Kubernetes resources or to Helm, so clusters that change the internal domain will need to override Gafaelfawr’s understanding of its internal URL in the Gafaelfawr chart configuration.
Because the ingress-nginx service must make cluster-internal calls to Gafaelfawr, ingress-nginx must be running in the same Kubernetes cluster as Gafaelfawr. Configurations where ingress-nginx runs outside of the cluster, including configurations where Gafaelfawr is running in a vCluster and ingress-nginx is running in the host cluster, are not supported.
Gafaelfawr also requires other specific ingress-nginx configuration, including NGINX configuration injected into the NGINX server configuration stanza. This is handled by the ingress-nginx Helm chart in Phalanx.
Network policy#
Both the browser and the token flows depend require that all access to the service, including access internal to the Kubernetes cluster, go through the ingress. The ingress is responsible for querying Gafaelfawr for authentication and scope-level access control. If the ingress is bypassed and one cluster service talks directly to another, this bypasses all authentication and authorization checks. The client making the request could also forge the HTTP headers that are normally generated by the ingress and claim to have a different identity and different group memberships than they actually have. Since the Notebook Aspect allows a user to run arbitrary code inside the Kubernetes cluster, including making requests to other services inside the cluster, this would allow any user with access to the Notebook Aspect to ignore other authentication and access control rules.
All Science Platform services protected by Gafaelfawr must therefore have a NetworkPolicy resource configured.
This resource prevents access to the service except via the ingress, thus forcing all requests to that service to go through the ingress.
Here is an example NetworkPolicy resource:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: "hips"
labels:
app.kubernetes.io/name: hips
app.kubernetes.io/instance: hips
spec:
podSelector:
matchLabels:
app.kubernetes.io/name: hips
app.kubernetes.io/instance: hips
policyTypes:
- Ingress
ingress:
- from:
# Allow inbound access from pods (in any namespace) labeled
# gafaelfawr.lsst.io/ingress: true.
- namespaceSelector: {}
podSelector:
matchLabels:
gafaelfawr.lsst.io/ingress: "true"
ports:
- protocol: "TCP"
port: 8080
The ingress-nginx Pod resource must then have the label gafaelfawr.lsst.io/ingress: "true" so that it is granted access to all services with a NetworkPolicy such as this one.
The efficacy of this approach relies on NetworkPolicy resources being enforced by the Kubernetes network layer.
This is not true by default; Kubernetes by itself does not implement NetworkPolicy.
Some networking add-on must normally be configured.
For example, GKE does this with Project Calico, but support may need to be explicitly turned on in the Kubernetes cluster configuration.
The Science Platform can still be deployed on Kubernetes clusters without NetworkPolicy enforcement.
However, be aware that this offers no authentication or access control protection within the cluster, including from users with access to the Notebook Aspect.
This may be an acceptable risk for deployments whose only users are trusted project members.
Storage#
This section deals only with storage for Gafaelfawr in each Science Platform deployment. For the storage of identity management information for each registered user when federated identity is in use, see COmanage.
Gafaelfawr storage is divided into two, sometimes three, backend stores: a SQL database, Redis, and optionally Firestore. Redis is used for the token itself, including the authentication secret. It contains enough information to verify the authentication of a request and return the user’s identity. The SQL database stores metadata about a user’s tokens, including the list of currently valid tokens, their relationships to each other, and a history of where they have been used from.
If the user’s identity information doesn’t come from LDAP, Redis also stores the identity information. Redis is also used to store rate limiting information and temporary data when acting as an OpenID Connect authentication provider.
Token format#
A token has two components: the key and a secret.
The key is visible to anyone who can list the keys in the Gafaelfawr Redis store or authenticate to the token API as the user.
Security of the system does not rely on keeping the key confidential.
Proof of possession comes from the secret portion of the token, which must match the secret value stored inside the token’s associated data for the token to be valid.
The secret is a 128-bit random value generated using os.urandom().
Tokens are formatted as gt-<key>.<secret>.
The gt- part is a fixed prefix to make it easy to identify tokens, should they leak somewhere where they were not expected.
Token data is stored in Redis under a key derived from the key portion of the token.
The secret is stored as part of the token data.
Wherever the token is named, such as in UIs, only the <key> component is given, omitting the secret.
Redis#
Gafaelfawr uses two separate Redis pools: one with persistent storage and one with only ephemeral (in-memory storage).
Persistent Redis#
Redis is canonical for whether a token exists and is valid. If a token is not found in Redis, it cannot be used to authenticate, even if it still exists in the SQL database. The secret portion of a token is stored only in Redis.
Redis stores a key for each token except for the bootstrap token (see Bootstrapping).
The Redis key is token:<key> where <key> is the key portion of the token, corresponding to the primary key of the token table.
The value is an encrypted JSON document with the following keys:
secret: The corresponding secret for this token
username: The user whose authentication is represented by this token
type: The type of the token (
session,user,service, etc.)service: The service to which the token was issued (only present for internal tokens)
scope: An array of scopes
created: When the token was created (in seconds since epoch)
expires: When the token expires (in seconds since epoch)
In addition, if user identity information does not come from LDAP, the following keys store identity information associated with this token. This information comes from OpenID Connect claims or from GitHub queries for information about the user.
name: The user’s preferred full name
email: The user’s email address
uid: The user’s unique numeric UID
gid: The user’s primary GID
groups: The user’s group membership as a list of dicts with two keys, name and id (the unique numeric GID of the group), where the id key is optional
If this data is set in Redis, that information is used by preference. If UID or GID information is not set in Redis and Firestore is configured (which is the case for deployments using CILogon and COmanage), those values are taken from Firestore, and the user’s primary GID is set to the same as their UID. For data not present in Redis or Firestore (if configured), LDAP is queried for the information. In other words, Gafaelfawr uses any data stored with the token in Redis by preference, then Firestore (if configured), then LDAP (if configured).
If LDAP is not configured and no source of that data was found, that data element is empty, is not included in API responses, and is not set in the relevant HTTP header (if any). For UID and GID, this is generally an error, except for synthetic users and service tokens that are only used in contexts where no POSIX file system access is done and thus UID and GID are not necessary.
In CILogon and COmanage deployments, none of these fields are set during token creation. All data comes from Firestore or LDAP. In GitHub deployments, all of these fields are set (if the data is available; in the case of name and email, it may not be). In OpenID Connect deployments, whether a field is set depends on whether that field is configured to come from LDAP or Firestore, or to come from the OpenID Connect token claims. In the latter case, the information is stored with the token. Child tokens and user tokens created from a token with user identity information will have that identity information copied into the data stored for the newly-created token in Redis.
Tokens created via the admin token API may have these fields set, in which case the values set via the admin token API are stored in Redis and thus override any values in LDAP, even if LDAP is configured.
The Redis key for a token is set to expire when the token expires.
The token JSON document is encrypted with Fernet using a key that is private to the authentication system. This encryption prevents an attacker with access only to the Redis store, but not to the running authentication system or its secrets, from using the Redis keys to reconstruct working tokens.
When the token is presented for authentication, the token data is retrieved from Redis using the key, and the secret provided is checked against the stored secret for that key. If the secrets do not match, the token is considered invalid and none of the retrieved data is returned to the user attempting to authenticate. Because the secret is in a Fernet-encrypted blog, someone who can list the keys in the Redis store but does not have the fernet encryption key cannot use those keys as tokens, since they have no access to the secret and thus cannot recreate the full token.
Ephemeral Redis#
As part of the internal OpenID Connect flow, Gafaelfawr has to issue an authentication code that can be redeemed later for a JWT. These codes are stored in an ephemeral Redis, since they exist only temporarily during an OpenID Connect authentication.
The code itself uses the same format as a token, except it starts with gc- instead of gt-.
It has the form gc-<key>.<secret>.
The <key> is the Redis key under which data for the code is stored.
The <secret> is an opaque value used to prove that the holder of the code is allowed to use it.
Wherever the code is named, such as in log messages, only the <key> component is given, omitting the secret.
The Redis key for the code is oidc:<key>, where <key> is the non-secret part of the code.
The value is an encrypted JSON document with the following keys:
code: The full code, including the secret portion, for verification
client_id: The ID of the client that is allowed to use this authorization
redirect_url: URL to which to redirect the user after authentication
token: The underlying session token for the user
created_at: When the code was issued
The Redis key is set to expire in one hour, which is the length of time for which the code is valid. As soon as the code is redeemed for a JWT, it is deleted from Redis, so it cannot be used again. Codes are not stored anywhere else, so once they expire or are redeemed they are permanently forgotten.
The code JSON document is encrypted with Fernet in exactly the same way that token information is encrypted.
The ephemeral Redis instance also stores rate limiting information. See Rate limiting for more information.
SQL database#
Cloud SQL is used wherever possible, via the Cloud SQL Auth proxy.
The proxy runs as a sidecar container in the main Gafaelfawr pods so that the proxy scales with instances of the web service.
Other Gafaelfawr pods (the Kubernetes operator, maintenance pods) use a shared instance of the proxy running as a stand-alone service that is only accessible to pods in the gafaelfawr namespace.
For deployments outside of GCS, an in-cluster PostgreSQL server deployed as part of the Science Platform is used instead.
Authentication to the SQL server, whether the proxy is used or not, is via a password injected as a Kubernetes secret into the Gafaelfawr pods.
The SQL database stores the following data:
Keys of all current tokens and their username, type, scope, creation and expiration date, name (for user tokens), and service (for internal tokens). Any identity data stored with the token is stored only in Redis, not in the SQL database.
Parent-child relationships between the tokens.
History of changes (creation, revocation, expiration, modification) to tokens, including who made the change and the IP address from which it was made.
List of authentication administrators, who automatically get the
admin:tokenscope when they authenticate via a browser;History of changes to admins, including who made the change and the IP address from which it was made.
Critically, the token secret is not stored in the SQL database, only in Redis. A token therefore cannot be recreated from the SQL database. Redis is the only authority for whether a token is valid.
Note that IP addresses are stored with history entries. IP addresses are personally identifiable information and may be somewhat sensitive, but are also extremely useful in debugging problems and identifying suspicious behavior.
The current implementation does not redact IP addresses, but this may be reconsidered at a later stage as part of a more comprehensive look at data privacy.
Firestore#
CILogon and COmanage Science Platform deployments use Firestore to manage UID and GID assignment, since COmanage is not well-suited for doing this. These assignments are stored in Google Firestore, which is a NoSQL document database.
Gafaelfawr uses three collections.
The users collection holds one document per username.
Each document has one key, uid, which stores the UID assigned to that user.
The groups collection holds one document per group name.
Each document has one key, gid, which stores the GID assigned to that group.
The counters collection holds three documents, bot-uid, uid, and gid.
Each document has one key, next, which is the next unallocated UID or GID for that class of users or groups.
They are initialized with the start of the ranges defined in DMTN-225.
If a user or group is not found, it is allocated a new UID or GID inside a transaction, linked with the update of the corresponding counter.
If another Gafaelfawr instance allocates a UID or GID from the same space at the same time, the transaction will fail and is automatically retried.
The bot-uid counter is used for usernames starting with bot-, which is the convention for service users (as opposed to human users).
There is no mechanism for deleting or reusing UIDs or GIDs; any unknown user or group is allocated the next sequential UID or GID, and that allocation fails if the bot UID or group GID space has been exhausted.
Gafaelfawr uses workload identity to authenticate to the Firestore database. The Firestore database is managed in a separate GCS project dedicated to Firestore, which is a best practice for Firestore databases since it is part of App Engine and only one instance is permitted per project.
Periodic maintenance#
Gafaelfawr also installs a Kubernetes CronJob that runs hourly to perform periodic maintenance on its data stores.
Delete SQL database entries for tokens that have expired, and add token change history entries noting the expiration. Tokens have an expiration set for their Redis key matching the underlying expiration of the token, so Redis doesn’t need similar maintenance.
Delete old entries from history tables to keep them from growing without bound. Only the past year of token change history is kept.
Bootstrapping#
Gafaelfawr provides a command-line utility to bootstrap a new installation of the token management system by creating the necessary database schema. To bootstrap administrative access, this step adds a configured list of usernames to the SQL database as admins. These administrators can then use the API or web interface to add additional administrators.
Gafaelfawr’s configuration may also include a bootstrap token.
This token will have unlimited access to the API routes /auth/api/v1/admins and /auth/api/v1/tokens and thus can configure the administrators and create service and user tokens with any scope and any identity.
Actions performed via the bootstrap token are logged with the special username <bootstrap>, which is otherwise an invalid username.
Caching#
In normal operation, Gafaelfawr often receives a flurry of identical authentication subrequests. This can happen from frequent API calls, but is even more common for users using a web browser, since each request for a resource from the service (images, JavaScript, icons, etc.) triggers another auth subrequest. Gafaelfawr therefore must be able to answer those subrequests as quickly as possible, and should not pass that query load to backend data stores and other services that may not be able to handle that volume.
This is done via caching.
Internal caching#
In most places where Gafaelfawr is described as retrieving information from another service, that data is cached in memory. Gafaelfawr also caches notebook and internal tokens for a specific token to avoid creating many new internal child tokens in short succession.
Gafaelfawr uses the following caches:
Caches of mappings from parent token parameters to reusable child notebook tokens and internal tokens. The cache is designed to only return a token if it satisfies the criteria for reuse of a notebook or internal token. Each of these caches holds up to 5,000 entries.
Three caches of LDAP data if LDAP is enabled: group membership of a user (including GIDs), group membership of a user (only group names, used for scopes), and user identity information (name, email, and UID, whichever is configured to come from LDAP). Each of these caches holds up to 1,000 entries, and entries are cached for at most five minutes.
Caches of mappings of users to UIDs and group names to GIDs, if Firestore is enabled. Each of these caches holds up to 10,000 entries. Since UIDs and GIDs are expected to never change once assigned, the cache entries never expire for the lifetime of the Gafaelfawr process.
All of these caches are only in memory in an individual Gafaelfawr pod. Deployments that run multiple Gafaelfawr pods for availability and performance will therefore have separate memory caches per pod and somewhat more cache misses.
Locking#
Gafaelfawr is, like most internal Science Platform applications, a FastAPI Python app using Python’s asyncio support. All caches are protected by asyncio locks using the following sequence of operations:
Without holding a lock, ask the cache if it has the required data. If so, return it.
Acquire a lock on the cache.
Ask again if the cache has the required data, in case another thread of execution already created and stored the necessary data. If so, return it.
Make the external request, create the token, or otherwise acquire the data that needs to be cached. If this fails, release the lock without modifying the cache and throw the resulting exception.
Store the data in the cache.
Release the lock on the cache.
The caches of UIDs and GIDs use a simple single-level lock. The LDAP and token caches use a more complicated locking scheme so that a thread of execution processing a request for one user doesn’t interfere with a thread of execution processing a request for a different user. That lock scheme works as follows:
Acquire a lock over a dictionary of users to locks.
Get the per-user lock if it already exists. If not, create a new lock for this user and store it in the lock dictionary.
Acquire the per-user lock.
Release the lock on the dictionary of users to locks.
The operation protected by the lock is then performed, and the per-user lock is released at the end of that operation.
NGINX caching#
Gafaelfawr runs as an NGINX auth_request subhandler.
By default, every request to any service running in the Science Platform results in an auth_request subrequest to Gafaelfawr.
Gafaelfawr is fairly efficient, so usually this doesn’t cause problems. However, if a Science Platform service regularly gets a flurry of requests in close succession, these Gafaelfawr calls can be inefficient and add unwanted load and latency. A typical example of this is web applications such as JupyterLab or the Portal Aspect, which may request large numbers of web resources (images and JavaScript libraries) or send high-frequency requests from JavaScript to support dynamic page updates.
In those cases, Gafaelfawr configures NGINX itself to cache the auth_request responses from Gafaelfawr for a short period of time.
This tells NGINX to reuse the first Gafaelfawr response for all subsequent responses, provided that neither the request method nor the Cookie or the Authorization headers have changed.
Selectively enabling this caching (done via a GafaelfawrIngress Kubernetes resource, discussed in Ingresses) significantly reduces the number of requests to Gafaelfawr for those applications, at the cost of not noticing session termination or expiration for up to the duration of the cache.
Kubernetes resources#
Gafaelfawr also runs a Kubernetes operator that maintains some Kubernetes resources for Science Platform services. The Kubernetes operator uses Kopf to handle the machinery of processing updates and recording status in Kubernetes objects.
Ingresses#
The supported way to create an Ingress resource for a protected resource is to use the GafaelfawrIngress custom resource definition.
Gafaelfawr (via the gafaelfawr-operator pod) will then create an Ingress resource based on that custom resource while performing sanity checks and generating the authentication-related NGINX annotations.
Using this custom resource makes it easier to maintain Science Platform services, since future versions of Gafaelfawr can adjust the NGINX annotations as needed without requiring any changes to the underlying resource.
A typical GafaelfawrIngress resource looks like the following:
apiVersion: gafaelfawr.lsst.io/v1alpha1
kind: GafaelfawrIngress
metadata:
name: <service>
config:
loginRedirect: true
scopes:
all:
- <scope>
template:
metadata:
name: <service>
spec:
rules:
- host: <hostname>
http:
paths:
- path: "/<service>"
pathType: "Prefix"
backend:
service:
name: <service>
port:
number: 8080
The config portion contains the authentication and authorization configuration, and the template portion is copied mostly verbatim into the constructed Ingress resource.
For more details, see the Gafaelfawr documentation.
GafaelfawrIngress can, and should, also be used to create ingresses for services that don’t require authentication.
In this anonymous case, Gafaelfawr is invoked only to filter cookies and tokens out of the headers before the rqeuest is passed to the underlying service.
This prevents leaking security credentials to a service, where they could be stolen in the event of a service compromise.
For more details on why this is important, see SQR-051.
All ingresses created by Gafaelfawr from GafaelfawrIngress will have the label app.kubernetes.io/managed-by set to the value Gafaelfawr to allow easy detection of Gafaelfawr-managed ingresses.
Service tokens#
Normally, protected services will request a delegated token on behalf of the user and make other API calls using that token. However, in some cases services will need to make calls on their own behalf. Examples include administrative services for user provisioning, monitoring systems that need to forge user tokens to test as a user, and internal systems that are easier to deploy as individual microservices that need to authenticate to each other. This is done via service tokens.
Service tokens are requested via a GafaelfawrServiceToken custom Kubernetes resource.
That resource looks like the following:
apiVersion: gafaelfawr.lsst.io/v1alpha1
kind: GafaelfawrServiceToken
metadata:
name: <name>
namespace: <namespace>
spec:
service: bot-<service-name>
scopes:
- <scope-1>
- <scope-2>
This requests a service token be created with the username bot-<service-name> and having scopes <scope-1> and <scope-2>.
(All service token usernames must start with bot-.)
This service token will be stored in a Kubernetes Secret resource with the same name and in the same namespace as the GafaelfawrServiceToken resource.
That secret will have one data element, token, which will contain a valid Gafaelfawr service token with the properties described in the spec section of the GafaelfawrServiceToken resource.
Any labels or annotations on the GafaelfawrServiceToken resource will be copied to the created Secret resource.
The Secret will be marked as owned by the GafaelfawrServiceToken resource, so it will be automatically deleted by Kubernetes if the parent resource is deleted.
Gafaelfawr will watch for any modifications to the GafaelfawrServiceToken resource and update the Secret resource accordingly.
Gafaelfawr does not monitor changes to the generated Secret resource, such as deletion, and therefore will not react to them immediately.
However, every 30 minutes it will also check all Secret resources associated with GafaelfawrServiceToken resources and ensure that they are present and the tokens are still valid, regenerating them if necessary.
(They could become invalid if, say, the Redis store for Gafaelfawr was reset.)
Token API#
Gafaelfawr is a FastAPI application and documents its API via OpenAPI. Generated API documentation is available as part of the Gafaelfawr documentation.
The API is divided into two parts: routes that may be used by an individual user to manage and view their own tokens, and routes that may only be used by an administrator.
Administrators are defined as users with authentication tokens that have the admin:token scope.
The first set of routes can also be used by an administrator and, unlike an individual user, an administrator can specify a username other than their own.
All APIs return JSON documents. APIs that modify state expect JSON request bodies.
Errors#
HTTP status codes are used to communicate success or failure. All errors will result in a 4xx or 5xx status code.
All 4xx HTTP errors for which a body is reasonable return a JSON error body. To minimize the amount of code required on top of FastAPI, these errors use the same conventions as the internally-generated FastAPI errors, namely:
{
"detail": [
{
"loc": [
"query",
"needy"
],
"msg": "field required",
"type": "value_error.missing"
}
]
}
In other words, errors will be a JSON object with a details key, which contains a list of errors.
Each error will have at least msg and type keys.
msg will provide a human-readable error message.
type will provide a unique identifier for the error.
Pagination#
Pagination is only used for history queries, since they may return a large number of records. Users are not expected to have enough active tokens to require pagination for token lists.
To avoid the known problems with offset/limit pagination, such as missed entries when moving between pages, pagination for all APIs that require it is done via cursors. For the history tables, there is a unique ID for each row and a timestamp. The unique ID will normally increase with the timestamp, but may not (due to out-of-order ingestion). Entries are always returned sorted by timestamp.
Gafaelfawr uses an approach called keyset pagination. When returning the first page, the results will be sorted by timestamp and then unique ID and a cursor for the next page will be included. That cursor will be the unique ID for the last record, an underscore, and the timestamp for that record (in seconds since epoch). If the client requests the next page, the server will then request entries older than or equal to that timestamp, sorted by timestamp and then by unique ID, and excluding entries with a matching timestamp and unique IDs smaller than or equal to the one in the cursor. This will return the next batch of results without a danger of missing any.
The cursor may also begin with the letter p for links to the previous page.
In this case, the relations in the SQL query are reversed (newer than or equal to the timestamp, unique IDs greater than or equal to the one in the cursor).
The pagination links use the Link (see RFC 8288) header to move around in the results, and an X-Total-Count custom header with the total number of results.
Example headers for a paginated result:
Link: <https://example.org/auth/api/v1/history/token-auth?limit=100&cursor=345_1601415205>; rel="next"
X-Total-Count: 547
Links of type next, prev, and first will be included.
last is not implemented.
Token UI#
The token component of the identity management system also has a user-facing UI. From that UI, a user of the Science Platform can see their existing tokens, create or manage their user tokens, and see a history of changes to their tokens.
This UI is implemented in client-side JavaScript (using React) and performs all of its operations via the token API. This ensures that there is one implementation of any token operation, used by both the API and the UI. The API provides a login route to the UI that provides the CSRF token (see CSRF protection) and configuration information required to construct the UI.
Currently, the UI is maintained as part of Gafaelfawr and served as static web pages by the same web service that serves the token API and the auth subrequest handler for ingress-nginx. It uses Gatsby to compile the web UI into JavaScript bundles suitable for serving to a web browser. The current implementation is purely functional with no styling and a poor user interface, intended only as a proof of concept. In the future, this UI is likely to move into another Science Platform service responsible for browser UI for the Science Platform as a whole.
CSRF protection#
API calls may be authenticated one of two ways: by providing a token in an Authorization header with type bearer, or by sending a session cookie.
The session cookie method is used by the token UI.
Direct API calls will use the Authorization header.
All API POST, PATCH, PUT, or DELETE calls authenticated via session cookie must include an X-CSRF-Token header in the request.
The value of this header is obtained via a login route, used by the token UI.
This value will be checked by the server against the CSRF token included in the user’s session cookie.
Direct API calls authenticating with the Authorization header can ignore this requirement, since cross-site state-changing requests containing an Authorization header and a JSON payload are blocked by the web security model.
Cross-origin requests are not supported, and therefore the token API responds with an error to OPTIONS requests.
Quota#
Gafaelfawr calculates quota for each user from its configuration and from any temporary quota overrides created via its REST API. Dynamically-configured quota overrides are stored in the persistent Redis.
For all of the implementation details, see SQR-073.
Rate limiting#
Gafaelfawr directly enforces API rate limits, if any are configured, by counting the requests to a service that pass thorugh its ingress authentication route (see Ingress integration). The data tracking is done using the Python limits library using 15-minute fixed windows. Tracking data is stored in the ephemeral Redis instance.
More complex windowing and different window intervals may be added later if this proves insufficient.
Rate limiting information is returned for all successful requests in X-RateLimit-* headers.
Requests that are rejected due to rate limiting result in a 429 response with the same headers plus the standard HTTP Retry-After header.
See SQR-073 for all of the details.
Logging#
Gafaelfawr uses structlog (via Safir) to log all its internal messages in JSON.
It is run via uvicorn, which also logs all requests in the standard Apache log format.
Interesting events that are not obvious from the access logging done by uvicorn are logged at the INFO level.
User errors are logged at the WARNING level.
Gafaelfawr or other identity management errors are logged at the ERROR level.
For a detailed description of the attributes included in logs, see the Gafaelfawr documentation.
Client IP addresses#
Since it is running as either an auth request subhandler or as a service behind a Kubernetes ingress, Gafaelfawr is always running behind a proxy server and does not see the actual IP address of the client.
It will attempt to analyze the X-Forwarded-For HTTP header to determine the client IP address as determined by the proxy server.
(It does not attempt to log the client hostname.)
For this to work properly, ingress-nginx must be configured to generate full, chained X-Forwarded-For headers.
This is done by adding the following to the ConfigMap for ingress-nginx.
data:
compute-full-forwarded-for: "true"
use-forwarded-headers: "true"
See the NGINX Ingress Controller documentation for more details. This workaround would no longer be needed if this feature request for the NGINX ingress were implemented.
Kubernetes source IP NAT for ingress-nginx must also be disabled.
Do this by adding spec.externalTrafficPolicy to Local in the Service resource definition for the NGINX ingress controller.
This comes with some caveats and drawbacks.
See this Medium post for more details.
For the curious, here are the details of why these changes are required.
Determining the client IP from X-Forwarded-For is complicated because Gafaelfawr’s /auth route is called via an NGINX auth_request directive.
In the Kubernetes NGINX ingress, this involves three layers of configuration.
The protected service will have an auth_request directive that points to a generated internal location.
That internal location will set X-Forwarded-For and then proxy to the /auth route.
The /auth route configuration is itself a proxy that also sets X-Forwarded-For and then proxies the request to Gafaelfawr.
Because of this three-layer configuration, if NGINX is configured to always replace the X-Forwarded-For header, Gafaelfawr will receive a header containing only the IP address of the NGINX ingress.
The above configuration tells the NGINX ingress to instead retain the original X-Forwarded-For and append each subsequent client IP.
Gafaelfawr can then be configured to know which entries in that list to ignore when walking backwards to find the true client IP.
Unfortunately, this still doesn’t work if Kubernetes replaces the original client IP using source NAT before the NGINX ingress ever sees it.
Therefore, source NAT also has to be disabled for inbound connections to the NGINX ingress.
That’s done with the externalTrafficPolicy setting described above.
Monitoring#
The primary monitoring for Gafaelfawr is mobu, the continuous integration test system for the Rubin Science Platform. It uses the token API to create tokens for bot users and then uses those tokens to interact with various Science Platform services, which in turn tests routine authentication and authorization checks. Problmes are reported to a Slack channel via a Slack incoming webhook.
Gafaelfawr also supports notifying a Slack channel (also via an incoming webhook) for uncaught exceptions.
Once a day, a CronJob resource runs an audit check on Gafaelfawr’s data sources looking for inconsistencies.
Any found are reported to a Slack channel if the Slack incoming webhook is configured.
Metrics#
Gafaelfawr supports exporting metrics to Sasquatch, the Rubin Observatory metrics and telemetry service. This support is optional.
If enabled, Gafaelfawr uses the support for publishing metrics events in Safir to register possible event types with the Sasquatch schema registry and then publishes events to Kafka. Currently, all metrics are published as events with associated data fields, including some metrics published by the maintenance cron job that would be more correctly represented as gauge metrics.
For more details about the published events, see the Gafaelfawr documentation.
References#
Design#
- DMTN-169
Proposed design for access control to Butler, the system that manages read and write access to Rubin Observatory data.
- DMTN-182
Supplements DMTN-169 with a design for how Butler should make access control decisions for a given operation. Proposes that all access control decisions should be based on the user’s group membership as exposed by the identity management system.
- DMTN-225
Metadata gathered and stored for each user, including constraints such as valid username and group name patterns and UID and GID ranges.
- DMTN-234
High-level design for the Rubin Science Platform identity management system. This is the document to read first to understand the overall system.
- DMTN-253
High-level design for how to authenticate users for IDACs and provide information about their data access rights. IDAC authentication creates the most requirements for Gafaelfawr OpenID Connect support, so this tech note also contains more discussion and design considerations for the OpenID Connect authentication flow.
- SQR-044
Requirements for the identity management system. This document is now incomplete and partly out of date, but still provides useful detail of requirements that have not yet been incorporated into the design.
- SQR-071
Proposed design for supporting user impersonation by administrators. If implemented, the details as implemented will be incorporated into this document and DMTN-234.
- SQR-073
Design and implementation details for user quotas and API rate limiting.
Security#
- DMTN-193
General discussion of web security for the Science Platform, which among other topics suggests additional design considerations for the Science Platform ingress, authentication layer, and authorization layer.
- SQR-051
Discussion of credential leaks from the authentication system to backend services, and possible fixes and mitigations.
Implementation details#
The tech note you are reading is the primary document for the implementation details of the Science Platform. Other implementation tech notes are:
- DMTN-235
Lists the token scopes used by the identity management system, defines them, and documents the services to which they grant access.
- SQR-055
How to configure COmanage for the needs of the identity management component of the Science Platform.
- SQR-069
Documents the decisions, trade-offs, and analysis behind the current design and implementation of the identity management system.
- SQR-073
Design and implementation details for user quotas and API rate limiting.
Operations#
- Gafaelfawr
The primary component of the identity management system. Its documentation covers operational issues such as configuration and maintenance, and includes the detailed reference to its REST API.
- Phalanx
The configuration and deployment infrastructure for the Science Platform. Its documentation includes operational details on how to configure services to correctly use the identity management system.
Project documents#
These are higher-level documents discussing Vera C. Rubin Observatory and the Science Platform as a whole that contain information relevant to the design and implementation of the identity management system.
- LDM-554
General requirements document for the Science Platform. This includes some requirements for the identity management system.
- LSE-279
General discussion of authentication and authorization for Vera C. Rubin Observatory. This is primarily a definition of terms and very high-level requirements for identity management. The group naming scheme described in this document has been replaced with the scheme in DMTN-235.
- LPM-121
Information security policy and procedures for Vera C. Rubin Observatory. This document is primarily concerned with defining roles and responsibilities.
- RDO-013
The Vera C. Rubin Observatory Data Policy, which defines who will have access to Rubin Observatory data.
Vendor evaluations#
- SQR-045
Evaluation of CILogon COmanage for use as the basis of user identity management and group management.
- SQR-046
Evaluation of GitHub for use as the basis of user identity management and group management.
History#
- DMTN-094
Original design document for the identity management system, now superseded and of historical interest only.
- DMTN-116
Original implementation strategy for the identity management system, now superseded and of historical interest only.
- SQR-039
Problem statement and proposed redesign for the identity management system, which led (with numerous modifications) to the current design. This document contains a detailed discussion of the decision not to use JWTs in the authentication system, and to keep authorization information such as group credentials out of the authentication tokens.
- SQR-049
Original design of the token management system for the Science Platform, including its API and storage model. This has now been superseded by this document, and the API description there has been superseded by the API described in the Gafaelfawr documentation. Still of possible interest in this document are the Kafka design, the specification for the housekeeping process, the API for authentication history, and the details of the desired token UI.